Uno de los retos de un analista digital es pasar por diferentes procesos de limpieza, exploración y análisis de contenido para sacar buenas conclusiones y detectar nuevos escenarios e insights. Además, tiene que comprobar si las fuentes de datos son de dudosa calidad o no.
Y si hablamos de un analista digital, es muy probable que toda esa exploración pase por la herramienta más utilizada en el mundo de la analítica: Google Analytics. Pero seguro que también estará conectado a otras fuentes como Google Sheet, un CRM o base de datos, u otros ficheros de texto, en formato csv, y más.
Hoy en día, un analista digital no solo tendrá que tener conocimientos solo de usabilidad de la web, también de negocios, estadística, programación, base de datos, visualización de datos, además estar actualizado con las nuevas tecnologías.
Entre las herramientas que normalmente podemos incluir en nuestro “maletín” de explorador de los datos, sería la programación. Y algunos de nuestros aliados deben ser el lenguaje R o Python, siendo “sencillos” en su aprendizaje y muy útiles a la hora de ejecutar pequeños script, ya que tienen muchas librerías open-source.
Veamos qué ofrecen cada uno de ellos y cómo pueden ayudarnos al análisis y visualización de datos.

¿Por qué R?
R es un lenguaje generalista, con diversas librerías de análisis estadístico bastante potentes que pueden suplir el campo de aplicación R, cosa que no sucede con otros lenguajes como Python, por ejemplo.
R está pensado para explotar su potencial que es la “estadística”. Este fantástico lenguaje nos permite una primera toma de contacto con los datos debido a su flexibilidad por la exploración, limpieza y análisis a diferentes fuentes de datos, así como aplicar modelos y algoritmos predictivos puede ser de gran ayuda en el mundo de la análisis de datos.
Intro de R Studio
R Studio es un entorno gráfico para el lenguaje de programación R que facilita la creación y ejecución de scripts. También simplifica la instalación de los paquetes necesarios para la ejecución de aquellos scripts que los requieran.
R Studio utiliza una partición de la pantalla en diferentes secciones, de forma que todos los elementos necesarios se encuentran disponibles a un solo clic, incluidos el código fuente, los datos cargados y generados por dicho código, los resultados obtenidos, los gráficos generados, etc.
También facilita la integración con otros sistemas para la creación de informes en diferentes formatos (principalmente HTML o PDF).
Librería de Google Analytics en R
Entre las diferentes librerías en R para poder conectar y explorar los datos desde Google Analytics, hay dos en particular de lo que hablaré hoy.
Ambos están en el repositorio oficial del CRAN (googleAuthR y googleAnalyticsR). Su función es que se necesitan en una el token Google Analytics, mientras el otro habilitar Google Cloud y su API, con lo cual necesitaríamos tener activados:
- Google Cloud, habilitar el proyecto.
- Permiso de edición de Google Analytics.
Aspectos a considerar de Google Analytics
Durante la fase de exploración, consultaremos dimensiones y métricas de Google Analytics. SI no estás familiarizado con estas dos partes más importantes de analítica web, mi consejo es que consultes la guía oficial para conocer las más representativas.
Si, por el contrario, ya conoces la interfaz de Analytics y quieres ir más allá, puedes consultar la tool externa de exploración de estos datos a través de la otra API de Google Analytics, Query Explorer,** **y la extensión o complemento para Google Sheet que permite tener datos directamente en una hoja de cálculo.
Fase de Instalación y Autorización de GA
En esta fase cargaremos los paquetes necesarios, previamente necesitaremos una cuenta de Google Cloud (que nos vendrá bien también si en un futuro queremos utilizar Big Query).
Es importante tener una cuenta de Google Analytics que no sea ni demo, ni solo de lectura, ya que podría tener problemas con los permisos.
Cargamos las librerías y configurar los valores opcionales:
install.packages(“googleAuthR”)
install.packages(“googleAnalyticsR”)
library(googleAnalyticsR) library(RGoogleAnalytics) library(ggplot2) # para representar gráficamente los datos library(forecast) # para las predicciones seriales library(“tidyverse”)
Autorización GA con Google Cloud y ejecutamos
Autorizamos a través del token con nuestro account Google
ga_auth()
Comenzamos con la primera query de Google Analytics in R
Veamos el listado de los account de GA y la guardamos en una nueva variable:
account_list
Lo que estamos realizando aquí es simplemente a través del token generado por Google Analytics para habilitar desde nuestro account de Google Analytics el listado de Cuentas, Propiedades y Vistas para poder así trabajar con una cuenta específica.
## EDA (Exploratory Data Analysis)
El trabajo de exploración del dataset en R requiere de varios pasos para comprobar si existen valores nulos o vacíos, discrepancias que podemos arreglar, sustituir o eliminar. A este proceso se le llama EDA.
# Create a list of the parameters to be used in the Google Analytics query
# Get the Sessions by Month in 2018
gadata
Podéis ver el código [en este repositorio de GitHub][7].
Con nuestra pequeña query, que guardaremos en una nueva variable **gadata**, almacenaremos las sesiones en un periodo de un año, por ejemplo. Paralelamente podemos observar si existen sesiones igual a cero.
Comprobado que efectivamente no existen valores nulos ni ceros, procederemos a una representación gráfica con el librería **ggplot** del paquete instalado _ggplot2._
Representación gráfica de la dimensión date y métrica sessions
gadata %>% ggplot(aes(x=date, y=sessions)) + geom_point()
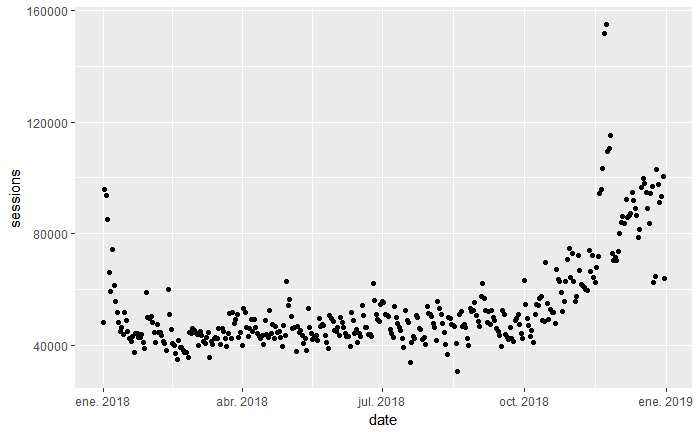
Y si queremos visualizar cada valor por tamaño según la sesión, entonces tendríamos este:
gadata %>%
ggplot(aes(x=date, y=sessions, size = sessions)) +
geom_point() +
theme(axis.text.x = element_text(angle = 90, hjust = 1))
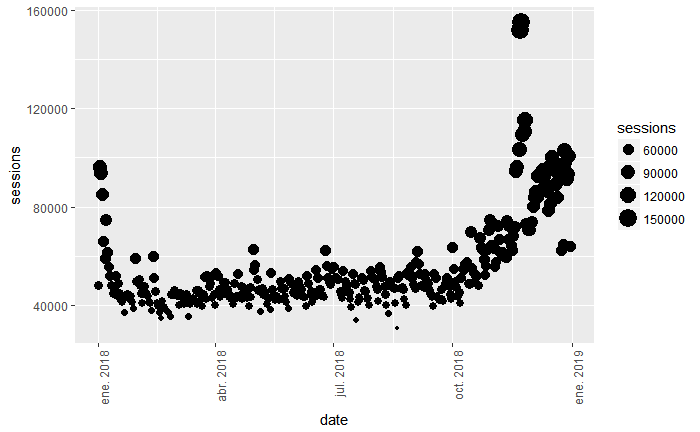
Y, si además le añadimos gradación por color de más oscuro a más claro, según el tamaño de las sesiones, obtendremos esto:
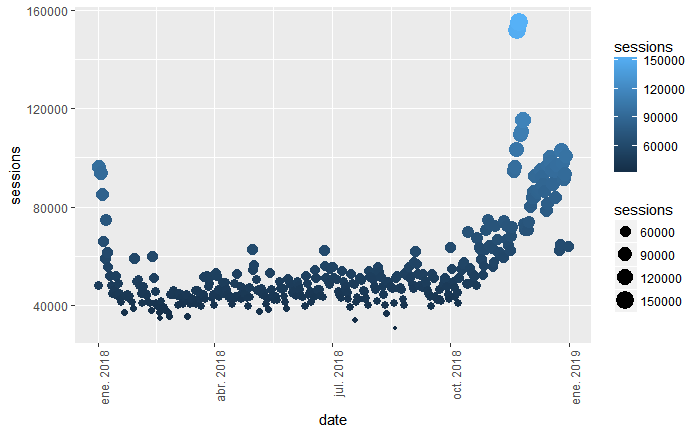
gadata %>%
ggplot(aes(x=date, y=sessions, size = sessions, color = sessions)) +
geom_point() +
theme(axis.text.x = element_text(angle = 90, hjust = 1))
Siguiendo la misma lógica, podemos añadir otras métricas de tráfico importantes (duración media, usuarios, páginas vistas, transacciones, eventos, etc), así que para tener una idea de la evolución o tendencia por periodo, podemos representar el gráfico de líneas:
gadata %>%
ggplot(aes(x=date,y=sessions,group=1)) +
geom_line() +
theme(axis.text.x = element_text(angle = 90, hjust = 1))
# some styles to rotate x-axis labels
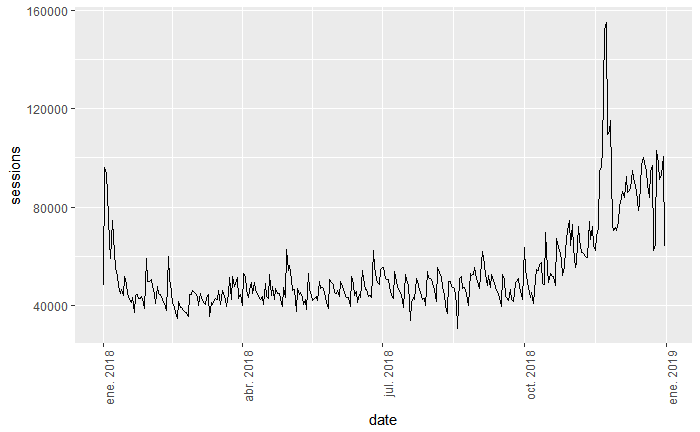
Ahora sí que se nota el pico máximo entre octubre y diciembre, nos hace pensar que este tráfico puede deberse al periodo entre el pre-Black Friday y durante Navidad (si es un retail tiene lógica). Y si queremos representar la tendencia, añadimos la línea de tendencia para que vayamos viendo la evolución del tráfico a lo largo del periodo observado:
gadata %>%
ggplot(aes(x = date, y = sessions) ) +
geom_point() +
geom_smooth() +
theme(axis.text.x = element_text(angle = 90, hjust = 1))
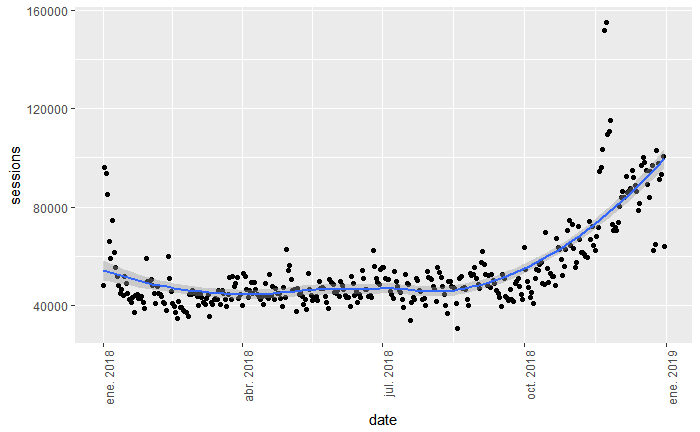
Con los primeros datos podemos observar que ha habido un periodo estable, con acciones puntuales (serán promociones) y el pico hasta navidad.
Ahora nos interesa conocer algo más de nuestros usuarios, segmentando así el tráfico según periodos más cortos.
Pasamos a detectar si existen diferencia durante los días de la semana y hora del día. Creamos una nuevo dataset con las métricas sesiones y duración media de sesión, por día de la semana.
# Añadimos la dimensión día de la semana y fecha - solo 1er semestre
gadata_2
## Segmentos de sesiones por día de la semana, franja horaria y categorías de dispositivos
![][13]
Podemos observar que los boxplot indicados son muy relevantes, aunque necesitamos profundizar más sobre temas de cuartiles, min y max, media y mediana.
Los puntos son nuestro "amigos" **outliers, **así que en casos puntuales estos tendrán que ser excluidos en algunos modelos y análisis. Lunes, martes y miércoles a primera vista tienen el mismo impacto, al igual que viernes y sábado.
## Duración media de sesión por día de la semana
![][14]
Los datos en la segunda métrica son expresados en segundos, y los días de la semana están según el formato anglosajón (0 = Domingo , 6 = Sábado).
Nos interesa ahora conocer la duración media de sesión por hora del día y el día de la semana. Una representación gráfica podría ser una matriz, con dimensiones día de la semana y hora, veamos un periodo de tiempo más corto, por ejemplo 6 meses.
Cargamos las librería correspondientes y guardamos en una nueva variable el dataframe:
library(“RColorBrewer”)
gadata_3
Podría ejecutarlo para verlo, pero para una correcta lectura de los días de la semana, sustituyamos los números por nombres, ordenando así los días de la semana:
gadata_3$dayOfWeekName
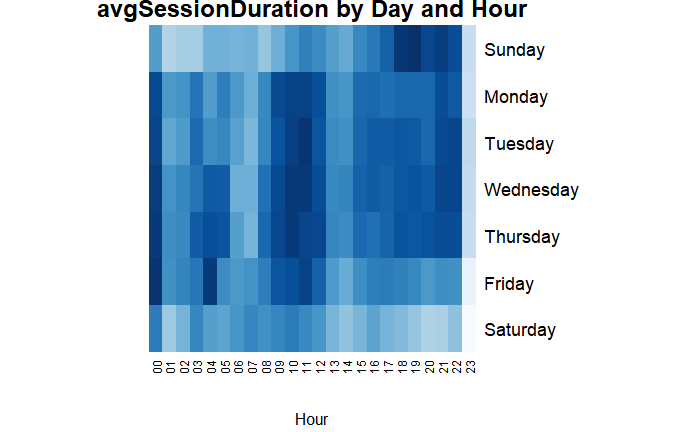
Con esta matriz se puede observar que las franjas horarias de 8:00 a 12:00 de lunes a viernes tienen mayor impacto por duración promedio, aunque se observan picos desde las 21:00 a las 00:00 los martes, miércoles y jueves.
Sábado es el día más tranquilo comenzando desde el viernes por la tarde, siguiendo hasta el domingo donde se observa un pico a partir de las 17:00 hasta las 22:00. Interesante para preparar campañas publicitarias o remarketing en estos horarios.
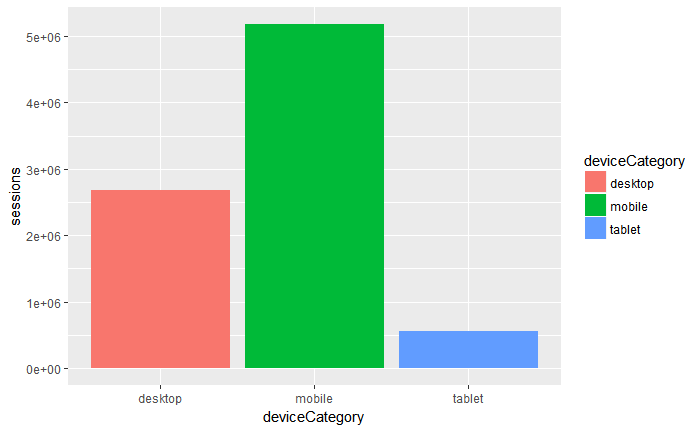
Seguimos ahora con la segmentación por categoría de dispositivos. No es lo mismo con equipo de escritorio que con móvil o tablet. Así que vamos con la creación de una nueva variable y con dimensión **deviceCategory. **
Otra visualización a realizar e interesante, sería la comparación por dispositivo.
gadata_4 % ggplot(aes(deviceCategory, sessions)) +
geom_bar(aes(fill = deviceCategory), stat=“identity”)
# plot avgSessionDuration with `deviceCategory`
gadata_4 %>%
ggplot(aes(deviceCategory, avgSessionDuration)) +
geom_bar(aes(fill = deviceCategory), stat="identity")
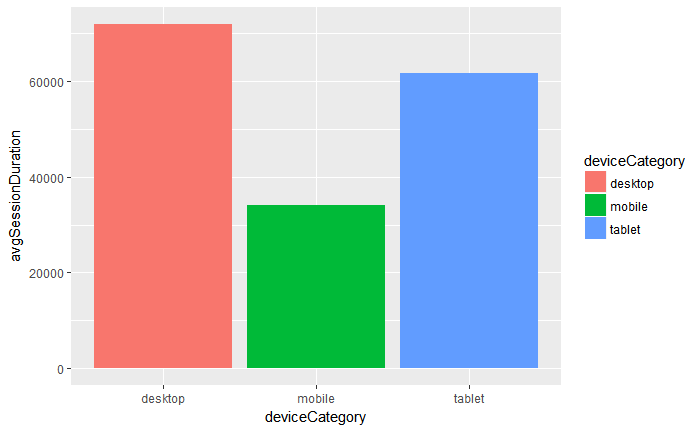
Con la segmentación por categoría de dispositivos podemos observar que tenemos mucho tráfico entrante por móvil, pero la duración promedio es muy baja.
Dato interesante si queremos utilizar como medio de “prospecting” el dispositivo móvil, pero también mejorar la conversión en desktop. El objetivo es crear finalmente un proyecto CRO y analizar muchos otros aspectos de usabilidad.
En este primer post hemos realizado una exploración de los datos integrando la API de Google Analytics en RStudio y como resultado unos cuantos ejemplos útiles a la hora de generar Insights.
En la segunda parte veremos algo más de inferencia estadística y aplicaremos algún modelo de predicción, que nos será de utilidad a la hora de buscar patrones y tendencias.
Si quieres tener acceso al repositorio, puedes acceder a él a través de este link.
(FUENTE ORIGINAL)[https://www.paradigmadigital.com/dev/analitica-web-r-analisis-visualizacion-datos/]