En este post (y próximas entradas) profundizaré más sobre los aspectos y detalles de la herramienta de Business Intelligence, Google Data Studio. Desde que Google adquiriera Looker en 2019 para poder competir con las 3 bigs ya mencionadas para la consultora Gartner en post anteriores (PowerBI, Tableau y Qlik), Google Data Studio sigue siendo una de las soluciones de uso libre, en formato SaaS, con muchas más novedades y que deja bastante libertad a la hora de crear report y, tal vez, dashboard dinámicos. Pero, ¿cómo podemos sacarle partido para la creación de nuevos dashboards y que no sean siempre las herramientas de medición web como Google Analytics o ficheros csv importados?
Google BigQuery como fuente de datos de Data Studio
Ya comentamos las diferencias entre un proveedor de BI y otro, además del coste, usabilidad, movilidad y capacidad de extraer conocimiento de los datos que importamos. Pero, la diferencia principal la encontramos en el número de conectores disponibles. A la hora de desarrollar la API, disponemos de un gran abanico de conectores que tienen las diferentes herramientas para ahorrar tiempo en la ingesta de los datos de diferentes fuentes. Actualmente Data Studio, siendo propiedad de Google, dispone de más de 50 conectores asociados a la familia Cloud, como BigQuery o SQL.
Primer Tutorial con BigQuery y pequeñas queries en SQL
El tutorial de hoy será sencillo y servirá como punto de partida la “nube”, utilizando uno de los dataset en formato libre de uso disponible en la web oficial donde existen actualmente un gran abanico para explorar y realizar nuestras pequeñas operaciones de carga parciales / totales, análisis de BI y creación de gráficos.
Este tutorial será un avance de lo que podríamos ser capaces en lo que respecta a crear nuevos gráficos e insights. Además, el dataset utilizado podría superar el terabyte de información, así que la mejor forma es a través de un sistema de ingesta de datos rápido y eficiente, ¡y no muy caro!
El ejemplo es sencillo. Realizaremos un volcado a la herramienta de BI; o, también, podemos realizar consultas SQL para detectar patrones.
Lanzando las consultas queries en SQL
Es importante distinguir entre MySQL y SQL de BigQuery. Exactamente tienen las mismas sintaxis, menos algunas excepciones a la hora de manipular fechas, arrays, listas anidadas, y que, además, BigQuery tiene su propia librería de auto Machine Learning que veremos en un próximo post.
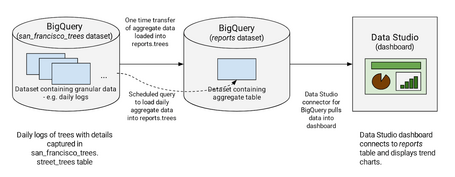
Aquí va la primera consulta query: una vez conectados seremos capaces de encontrar el número de árboles plantados cada mes.
Los objetivos serán:
- ¿Qué especies de árboles se plantaron?
- ¿Quién es el cuidador de los árboles?
- Dirección de los árboles plantados.
- Información del sitio del árbol.
SELECT
TIMESTAMP_TRUNC(plant_date, MONTH) as plant_month,
COUNT(tree_id) AS total_trees,
species,
care_taker,
address,
site_info
FROM
`bigquery-public-data.san_francisco_trees.street_trees`
WHERE
address IS NOT NULL
AND plant_date >= TIMESTAMP_SUB(CURRENT_TIMESTAMP(), INTERVAL 365 DAY)
AND plant_date < TIMESTAMP_TRUNC(CURRENT_TIMESTAMP(), DAY)
GROUP BY
plant_month,
species,
care_taker,
address,
site_info
Copy.
La consulta realizada será en formato SQL standard después de utilizar su propio motor BigQuery engine. Aquí podéis encontrar más detalles sobre su funcionamiento.
La vista que obtendremos será muy similar a esta:
Generamos datos en real time
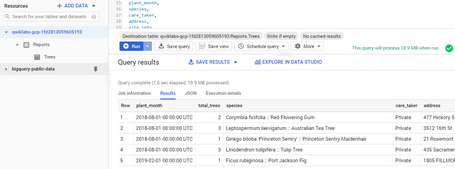
Si queremos obtener datos en real time y un dashboard siempre actualizado, entonces con esta pequeña modificación en la consulta seremos capaces de obtener datos de manera incremental cada día. La query es la siguiente, donde entre sus condiciones WHERE estamos indicando el parámetro Date.
SELECT
TIMESTAMP_TRUNC(plant_date, MONTH) as plant_month,
COUNT(tree_id) AS total_trees,
species,
care_taker,
address,
site_info
FROM
`bigquery-public-data.san_francisco_trees.street_trees`
WHERE
address IS NOT NULL
AND plant_date >= TIMESTAMP_SUB(CURRENT_TIMESTAMP(), INTERVAL 1 DAY)
AND plant_date < TIMESTAMP_TRUNC(CURRENT_TIMESTAMP(), DAY)
GROUP BY
plant_month,
species,
care_taker,
address,
site_info
Copy.
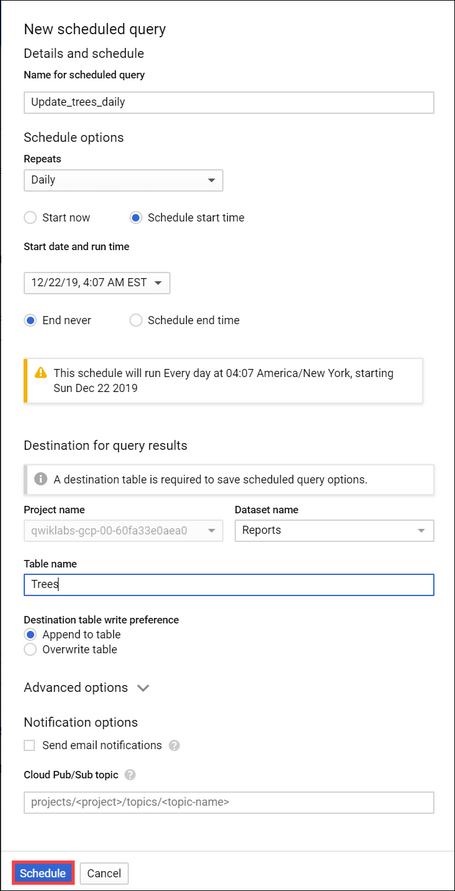
Sucesivamente habilitaremos la opción NEW SCHEDULED QUERY para que tengamos la opción de real time en nuestros informes.
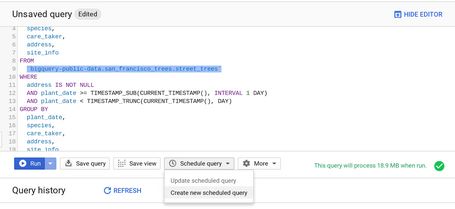
La opción siguiente es para que los datos nuevos serán añadidos en lugar de tener que suscribirlos.
Analizando los datos en Google BigQuery
Podemos, en este punto, realizar todo tipos de operaciones, realizar nuestros descubrimientos, detectar patrones y si queremos ir avanzando con los análisis, buscar pequeños estadísticos básicos, tareas de limpieza y preparación, manipulación, discretización y factorización, métodos de clustering y asociaciones, hasta aplicar algoritmos de clasificaciones, predicciones, etc. A vosotros, analistas, os dejaré esta tarea como pendiente de realizar ;-).
Realizamos la conexión en Google Data Studio
Una vez estudiadas las variables y las base de datos, realizamos la conexión. Para ello vamos en Crear:
Una vez que escogemos la opción de Data Source:
Procedemos con la conexión en BigQuery:
La conexión que estamos realizando es para utilizar el repositorio público disponible como Public Data-Sets, y una vez seleccionado el proyecto asociado a nuestra cuenta, buscaríamos tree y ya nos saldrán los tres datasets (podemos indistintamente utilizar new york o san francisco).
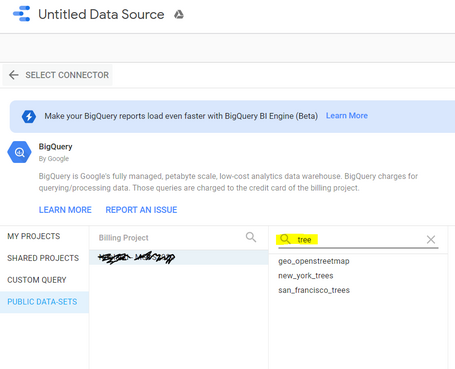
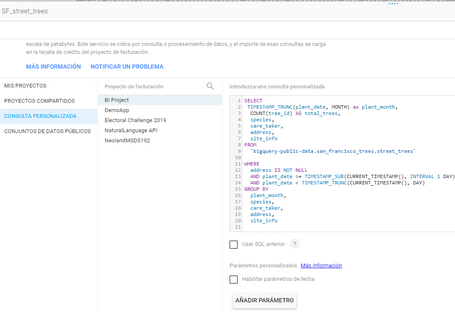
Y lanzamos nuestra consulta directamente con BigQuery si queremos realizar nuestra personalización, pero directamente en Data Studio. También podemos realizar tareas de asignación de parámetros y jugar con ellas para variables dinámicas.
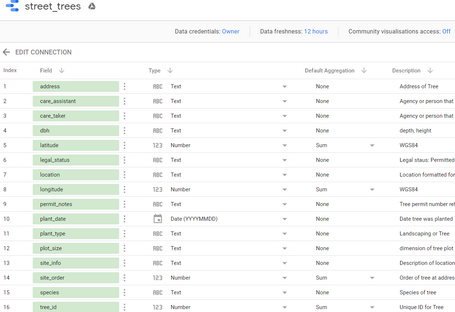
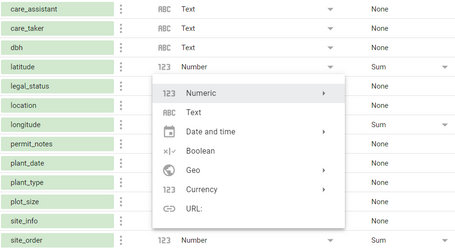
Una vez que obtengamos los datos vamos a realizar las separaciones correctamente entre las dimensiones y métricas. Según la guía oficial de Data Studio, las dimensiones son nuestras variables categóricas (fechas, nombres y tipo de árboles, lat y lon, ciudades, booleanos, etc), básicamente todas aquellas que son nombres y están marcada en VERDE. Las métricas serán todas variables numéricas (enteros, decimales, porcentajes, monedas), y estarán marcadas en AZUL.
Podemos, o bien, importar todas por defecto o abrimos otra tarea a nuestro backlog para realizar todo tipo de operaciones de creación de nuevos campos calculados o nuevas métricas. Es importante esta tarea, que podemos podemos siempre volver atrás para realizarla.
Además, a través del BigQuery Engine, podemos actualizar estas nuevas variables con el tiempo sin miedo de perder la consistencia de los datos (siempre que el origen se mantenga como tal).
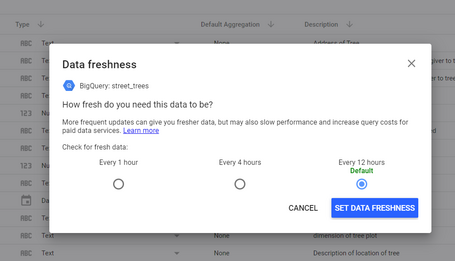
La otra novedad que tiene Data Studio es el poder de refrescar los datos de forma automática: cada hora, cada 4 horas o cada 12. Para no lanzar muchas consultas, podemos dejar por defecto la última opción, ya que la tarea de planificación en BigQuery es diaria.
Existen muchas trampas a la hora de convertir una dimensión / métrica en un tipo de variable. Si hace falta, es preferible comprobarlas antes de “dibujar”.
Llegados a este punto, podemos crear un report o realizar una exploración. La diferencia es que en la primera hay que realizar todo tipo de gráficos, segmentos y filtros, y será nuestra obra maestra final; y en la segunda, nos da la oportunidad de visualizar en vista previa los datos. Muy útil si queremos ver el formato antes de crear el report. De la misma forma también se puede realizar desde BigQuery, ya que dispone del mismo “botón”.
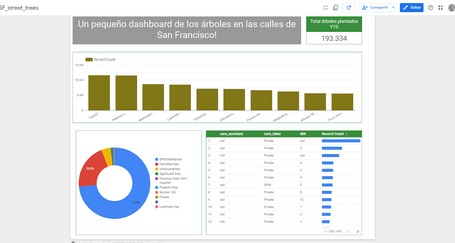
Masterpiece time! Es hora de “dibujar” la obra maestra
Seguramente tú lo harías mejor, pero este sería un ejemplo de cómo presentar los datos desde la fuente BigQuery de Google y Data Studio.
Os adjunto el link para consultarlo online también: http://paradig.ma/dashboard-data-studio
Gracias y ¡hasta el próximo post!